臺大代表隊勇奪國際學生超級電腦叢集競賽總冠軍
瀏覽器版本過舊,或未開啟 javascript
請更新瀏覽器或啟用 javascript
更新日期:114年11月19日
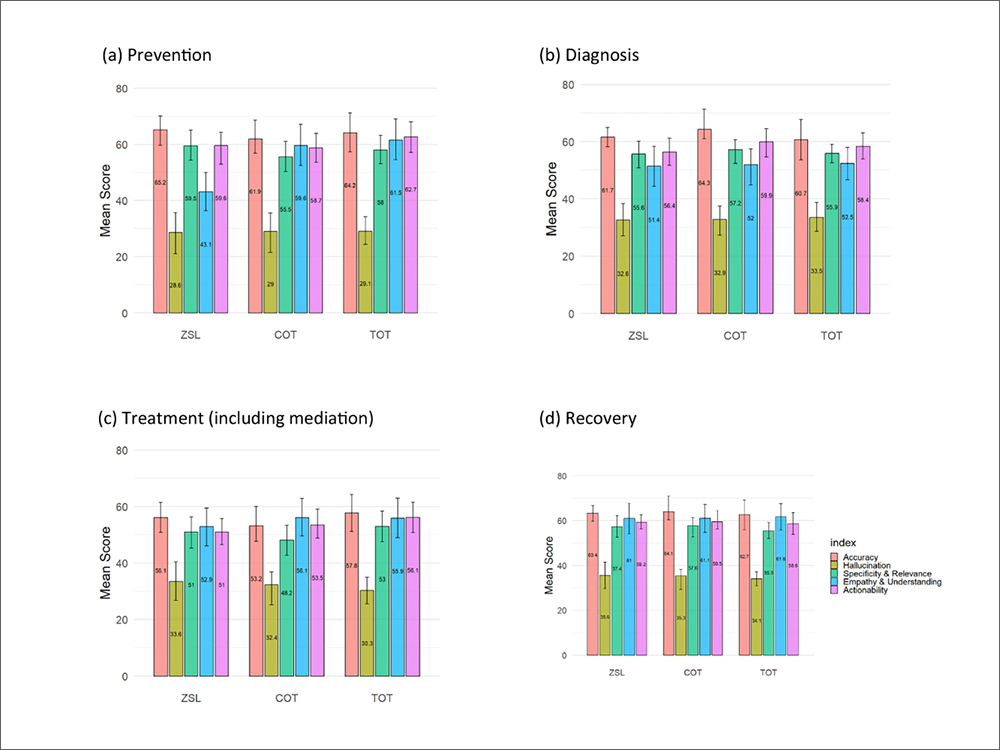
中風照護四個階段中,各項提問方式在五個面向的平均表現分數
中風是全球主要的死亡與失能原因之一,且對社經弱勢族群影響尤為嚴重。近年生成式人工智慧快速發展,許多人開始好奇這些AI能否協助提供正確的中風預防與照護資訊?
近期由臺灣大學公共衛生學院與哈佛大學公共衛生學院 (Harvard T.H. Chan School of Public Health) 合作的研究團隊,針對3個生成式大型語言模型 (LLMs):ChatGPT、Claude與Gemini進行效能評估。研究人員迷擬真實病人提問的情境,涵蓋中風照護的4個階段:預防、診斷、治療、復健,並採用不同「提問方式」(prompt engineering):ZSL (Zero-shot Learning)、COT (Chain of Thought) 和TOT (Talking Out Your Thoughts)。臨床醫師再依據5個面向進行評分:準確性、幻覺(提供錯誤資訊)、具體性、同理心與可執行性,並以醫師資格考試的及格標準(60分)作為最低合格門檻。此篇研究已發表於國際頂尖期刊《npj Digital Medicine》。
結果顯示,雖然不同提問方式各有優勢,但整體而言,3個LLMs的表現仍不理想,且在不同階段與評分面向間缺乏一致性,多數結果都低於臨床可接受水準。在各類提示工程方法中,TOT於同理心與可執行性的表現較佳;ZSL能提供精簡的回答,且產生「幻覺」(hallucination) 的情形較少;而COT在診斷問題時的邏輯則較為清晰。
研究團隊指出,生成式AI在提供健康資訊時,目前仍難以達到臨床專業標準。特別是在面臨如中風等急性病況時,若AI提供錯誤或過度簡化的回答,將可能導致治療延誤。
研究團隊表示,生成式AI具備縮小健康不平等與紓解醫療人力短缺的潛力,其實是對於醫療資源不足的地區更具意義。要實現這項潛力,除了持續推進大型語言模型等醫療AI技術外,也應加強患者與照護者如何有效提問,讓AI回覆更安全且具臨床價值。同時,必須透過嚴謹的監管機制、臨床驗證與專業醫師的監督,確保所提供的資訊安全、正確、並符合實際臨床情境。